Hämta hela webbsidorna i Firefox med ScrapBook
Behöver du spara en webbsida eller hemsida så att du kan visa den offline ? Ska du vara offline under en längre tid, men vill kunna bläddra igenom din favoritwebbplats? Om du använder Firefox, finns det ett Firefox-tillägg som kan lösa ditt problem.
ScrapBook är en fantastisk Firefox-förlängning som hjälper dig att spara webbsidor och organisera dem på ett mycket enkelt sätt att hantera. Den riktigt coola grejen om denna tillägg är att den är väldigt lätt, snabb, cachar en lokal kopia av en webbsida nästan perfekt och stöder flera språk. Jag testade det på flera webbsidor med mycket grafik och fina CSS-stilar och var förvånansvärt glad att se att offline-versionen såg ut exakt samma som onlineversionen.
Du kan använda ScrapBook för följande ändamål:
- Spara en enda webbsida
- Spara snippet eller del av en enda webbsida
- Spara en hel webbplats
- Ordna samlingen på samma sätt som bokmärken med mappar, undermappar
- Fulltextsökning och snabb filtreringssökning av hela samlingen
- Redigering av den samlade webbsidan
- Text / HTML redigera funktion som liknar Opera's Notes
Installera ScrapBook
Om du kör den senaste versionen av Firefox, vilket är v33 för mig med det här skrivet, måste du justera några inställningar så att du kan använda ScrapBook korrekt. Som standard visas inte ScrapBook-ikonen någonstans, så det enda sättet du kan använda är att högerklicka på en webbsida. Lägg till knappen till verktygsfältet eller till menyn genom att högerklicka var som helst på verktygsfältet och välj Anpassa .
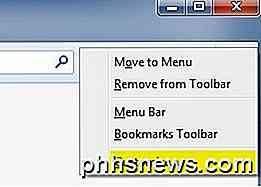
På skärmen Anpassa ser du ikonen ScrapBook på vänster sida. Gå vidare och dra det till antingen verktygsfältet överst eller till menyn. Fortsätt sedan och klicka på knappen Ändra Anpassa.
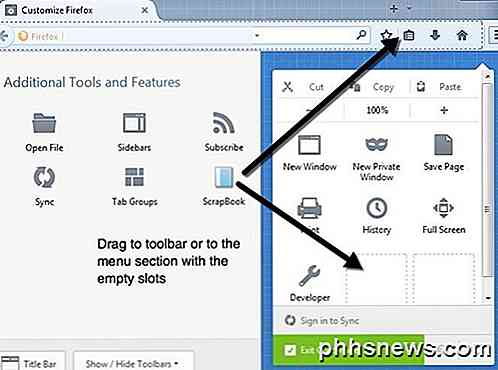
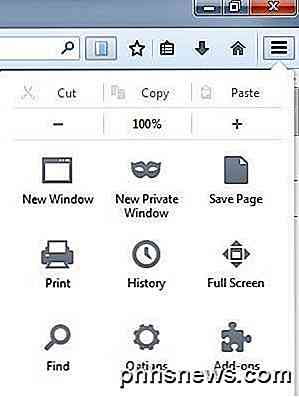
Innan vi börjar använda ScrapBook för att spara en webbplats kanske du vill ändra inställningarna för tillägget. Du kan göra det genom att klicka på menyknappen längst upp till höger (tre horisontella linjer) och sedan klicka på Add-ons .
Klicka nu på Extensions och klicka sedan på alternativknappen bredvid ScrapBook-tillägget.
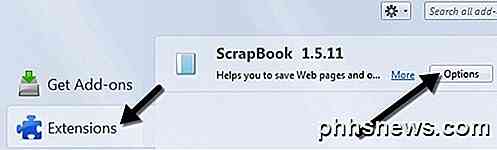
Här kan du ändra kortkommandon, platsen där data lagras och andra mindre inställningar.
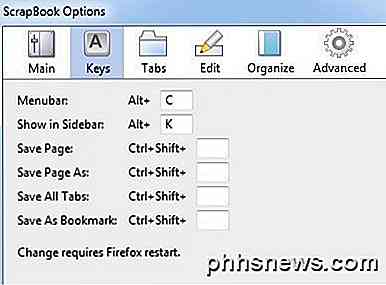
Använda ScrapBook för att hämta webbplatser
Låt oss nu komma in i detaljerna om att faktiskt använda programmet. Först, ladda webbplatsen du vill ladda ner webbsidor för. Det enklaste sättet att starta en nedladdning är att högerklicka var som helst på sidan och välj antingen Spara sida eller Spara sida som i längst ned på menyn. Dessa två alternativ läggs till av ScrapBook.
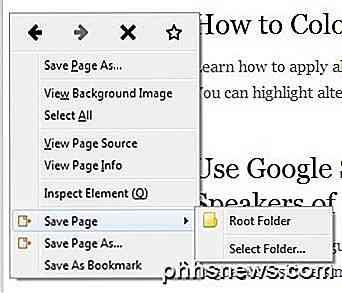
Spara sidan låter dig välja en mapp och spara sedan bara den aktuella sidan automatiskt. Om du vill ha fler alternativ, som jag normalt gör, klickar du på alternativet Spara sidan som. Du får en annan dialog där du kan välja och välja bland många alternativ.
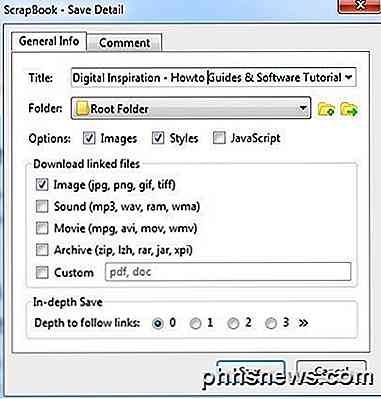
De viktiga avsnitten är avsnittet Alternativ, Hämta länkade filer och alternativa alternativ för djupgående Spara . Som standard laddar ScrapBook bilder och stilar, men du kan lägga till JavaScript om en webbplats kräver det för att fungera korrekt.
Nedladdade länkade filer kan bara hämta länkade bilder, men du kan också ladda ner ljud, filmfiler, arkivera filer eller ange exakt vilken typ av filer som ska hämtas. Det här är ett mycket användbart alternativ om du är på en webbplats som har en massa länkar till en viss typ av fil (Word-dokument, PDF-filer, etc.) och du vill ladda ner alla relaterade filer snabbt.
Slutligen är alternativet Fördjupning hur du skulle gå om nedladdning av större delar av en webbplats. Som standard är den satt till 0, vilket innebär att det inte följer några länkar till andra sidor på webbplatsen eller någon annan länk för den delen. Om du väljer en, hämtar den aktuella sidan och allt som är länkat från den sidan. Djup 2 kommer att hämtas från den aktuella sidan, den 1 länkade sidan och alla länkar från den 1 länkade sidan också.
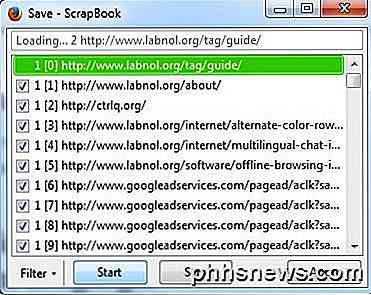
Klicka på Spara-knappen och det nya fönstret dyker upp och sidorna börjar hämtas. Du vill omedelbart trycka pausknappen och låt mig berätta varför. Om du bara låter ScrapBook springa, börjar den ladda ner allt från sidan, inklusive alla saker i källkoden som kan länka till en massa andra webbplatser eller annonsnätverk. Som du kan se i bilden ovan, utanför huvudwebbplatsen (labnol.org), laddar den ner annonser från googleadservices.com och något från ctrlq.org.
Vill du verkligen att annonserna ska dyka upp på webbplatsen medan du surfar den offline? Detta kommer också att slösa bort mycket tid och bandbredd, så det bästa är att trycka på Paus och klicka sedan på knappen Filter .
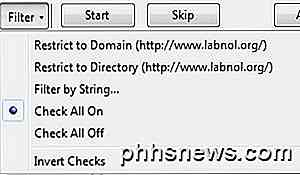
De bästa två alternativen är Begränsa till domän och begränsa till katalog . Normalt är de samma, men på vissa platser kommer de att vara olika. Om du vet exakt vilka sidor du vill kan du även filtrera efter sträng och skriva in din egen webbadress. Det här alternativet är fantastiskt eftersom det blir av med alla andra skräp och bara hämtar innehåll från den faktiska webbplatsen du är på snarare än från sociala medier, annonsnät etc.
Fortsätt och klicka på Start och sidorna börjar hämta. Tiden att ladda ner kommer att bero på din internetanslutningshastighet och exakt hur mycket på webbplatsen du hämtar. Tillägget fungerar bra för de flesta webbplatser och det enda problemet jag har stött på är att på vissa webbplatser är de webbadresser de använder för att länka till sitt eget innehåll absoluta webbadresser.
Problemet med absoluta webbadresser är att när du öppnar indexsidan i Firefox medan du är offline och försöker klicka på någon av länkarna, försöker den ladda från den faktiska webbplatsen istället för från den lokala cachen. I sådana fall måste du manuellt öppna nedladdningsmappen och öppna sidorna. Det är en smärta och jag har bara haft det på en handfull webbplatser, men det förekommer. Du kan se nedladdningsmappen genom att klicka på ScrapBook-knappen på verktygsfältet och sedan högerklicka på webbplatsen och välja Verktyg - Visa filer .
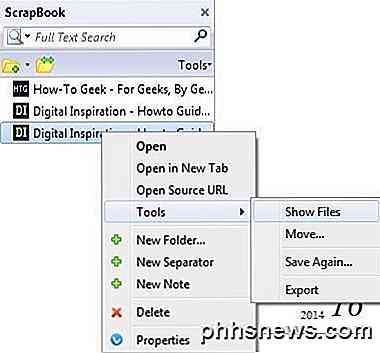
I Utforskaren sorterar du efter typ och rullar sedan ner till filerna heter HTML-dokument. Innehållssidorna är normalt standard_00x-filerna, inte index_00x-filerna.
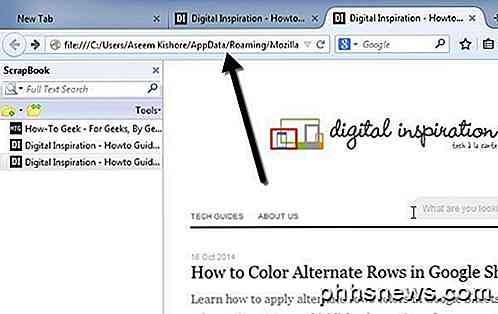
Om du inte använder Firefox och fortfarande vill ladda ner webbsidor till din dator, kan du också kolla in en mjukvara som heter WinHTTrack som automatiskt hämtar en hel webbplats för att senare söka offline. WinHTTrack använder dock mycket utrymme, så se till att du har tillräckligt med ledigt utrymme på hårddisken.
Båda programmen fungerar bra för nedladdning av hela webbplatser eller för nedladdning av enskilda webbsidor. I praktiken är nedladdning av en hel webbplats nästan omöjlig på grund av det massiva antalet länkar som genereras av CMS-program som WordPress, etc. Om du har några frågor, skriv en kommentar. Njut av!

OTT förklarar - varför har Windows fler virus än Linux och OS X?
Jag skriver det här inlägget eftersom jag nyligen hörde ett samtal mellan två vänner där man rekommenderade att vänten byter från Windows till Mac eller Linux eftersom de senare operativsystemen är viruslösa och aldrig får skadlig kod eller rootkits. Uhhh, fel. Helt fel. Tyvärr finns det många som tror på detta och tror att köpa en Mac eller installera Ubuntu skyddar dem på något sätt.Det finns viss sa

Kan jag använda två typer av DDR3-RAM med samma moderkort?
En möjlighet att uppgradera datorns maskinvara är alltid bra, men kan du använda två typer av DDR3-RAM på samma moderkort om du har begränsade resurser? Dagens SuperUser Q & A-inlägg har svar på en nyfiken läsarens fråga. Dagens Frågor och svar sessions kommer till vår tjänst med SuperUser-en indelning av Stack Exchange, en community-driven gruppering av Q & A-webbplatser.