Vad är karaktärkodningar som ANSI och Unicode, och hur skiljer de sig?
ASCII, UTF-8, ISO-8859 ... Du kanske har sett dessa konstiga monikrar flytande runt, men vad gör de betyder egentligen? Läs vidare när vi förklarar vilken teckenkodning som är och hur dessa akronymer hänför sig till den vanliga texten vi ser på skärmen.
Grundläggande byggstenar
När vi pratar om skrivspråk talar vi om bokstäver som byggstenar av ord, som sedan bygger meningar, stycken och så vidare. Brev är symboler som representerar ljud. När du pratar om språk, pratar du om grupper av ljud som kommer samman för att bilda någon form av mening. Varje språksystem har en komplex uppsättning regler och definitioner som styr dessa betydelser. Om du har ett ord är det värdelöst om du inte vet vilket språk det är från och du använder det med andra som talar det språket.

(Jämförelse av Grantha, Tulu och Malayalam-skript, Bild från Wikipedia)
I världen av datorer använder vi termen "karaktär". Ett tecken är ett abstrakt begrepp definierat av specifika parametrar, men det är den grundläggande betydelseenheten. Latinet 'A' är inte detsamma som en grekisk 'alfa' eller en arabisk 'alif' eftersom de har olika sammanhang - de är från olika språk och har något annorlunda uttal - så vi kan säga att de är olika karaktärer. Den visuella representationen av ett tecken kallas en "glyph" och olika uppsättningar av glyfer kallas teckensnitt. Grupper av tecken tillhör en "set" eller en "repertoar".
När du skriver ett stycke och ändrar teckensnittet ändrar du inte bokstavens fonetiska värden, du ändrar hur de ser ut. Det är bara kosmetiskt (men inte obetydligt!). Vissa språk, som gamla egyptiska och kinesiska, har ideogram; Dessa representerar hela idéer istället för ljud, och deras uttalanden kan variera över tid och avstånd. Om du ersätter en karaktär för en annan, ersätter du en idé. Det är mer än att bara ändra bokstäver, det ändrar ett ideogram.
Teckenkodning

(Bild från Wikipedia)
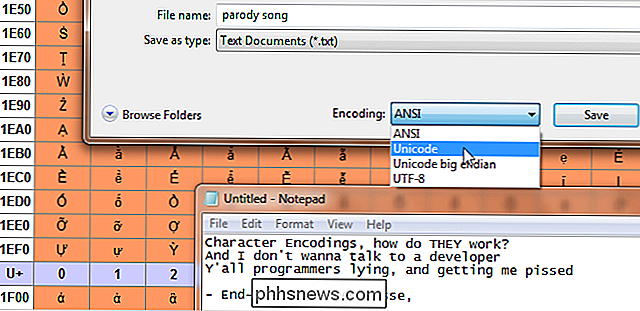
När du skriver något på tangentbordet eller laddar en fil, vet hur datorn ska visas? Det är vad teckenkodning är för. Text på din dator är inte egentligen bokstäver, det är en serie parade alfanumeriska värden. Teckenkodningen fungerar som en nyckel för vilka värden motsvarar vilka tecken, precis som hur ortografi dikterar vilka ljud som motsvarar vilka bokstäver. Morskod är en typ av teckenkodning. Det förklarar hur grupper av långa och korta enheter som piper representerar tecken. I Morse-koden är tecknen bara engelska bokstäver, siffror och fullstopp. Det finns många datorkodkodningar som översätts till bokstäver, siffror, accentmarkeringar, skiljetecken, internationella symboler och så vidare.
Ofta om detta ämne används termen "kodsidor" också. De är i huvudsak teckenkodningar som används av specifika företag, ofta med små förändringar. Exempelvis är koden för Windows 1252-koden (tidigare känd som ANSI 1252) en modifierad form av ISO-8859-1. De används mest som ett internt system för att referera till standard och modifierade teckenkodningar som är specifika för samma system. I början var teckenkodning inte så viktigt eftersom datorer inte kommunicerade med varandra. Med internet som stiger till framträdande och nätverk är ett vanligt förekommande, har det blivit en allt viktigare av våra dagliga liv utan att vi ens inser det.
Många olika typer
(Bild från sarah sosiak)
Det finns många olika teckenkodningar där ute, och det finns många skäl till det. Vilken teckenkodning du väljer att använda beror på vad dina behov är. Om du kommunicerar på ryska, är det meningsfullt att använda en teckenkodning som stöder cyrillisk väl. Om du kommunicerar på koreanska, vill du ha något som representerar Hangul och Hanja bra. Om du är matematiker, vill du ha något som har alla de vetenskapliga och matematiska symbolerna representerade bra, liksom de grekiska och latinska glyferna. Om du är en prankster kanske du kan dra nytta av upp och ner text. Och om du vill att alla typer av dokument ska ses av någon person, vill du ha en kodning som är ganska vanlig och lättillgänglig.
Låt oss ta en titt på några av de vanligaste.

(Utdrag av ASCII-tabellen, Bild från asciitable.com)
- ASCII - Den amerikanska standardkoden för informationsutbyte är en av de äldre teckenkodningarna. Det var ursprungligen utformat baserat på telegrafiska koder och utvecklades med tiden för att inkludera fler symboler och några nuföråldda, icke-tryckta kontrolltecken. Det är nog så grundläggande som du kan få när det gäller moderna system, eftersom det är begränsat till det latinska alfabetet utan accenterade tecken. Dess 7-bitars kodning möjliggör endast 128 tecken, varför det finns flera inofficiella varianter som används över hela världen.
- ISO-8859 - Den internationella organisationen för standardiseringens mest använda grupp av teckenkodningar är nummer 8859 Varje specifik kodning är betecknad med ett tal, ofta prefixat av en beskrivande moniker, t.ex. ISO-8859-3 (Latin-3), ISO-8859-6 (Latin / Arabisk). Det är en superset av ASCII, vilket innebär att de första 128 värdena i kodningen är desamma som ASCII. Det är dock 8-bitars och tillåter 256 tecken, så det bygger sig bort därifrån och innehåller ett mycket större antal tecken, där varje specifik kodning fokuserar på en annan uppsättning kriterier. Latin-1 inkluderade en massa accentuerade bokstäver och symboler, men ersattes senare med en reviderad uppsättning som heter Latin-9, som innehåller uppdaterade glyfer som Euro-symbolen.
(Utdrag av tibetanskt skript, Unicode v4, från unicode.org)
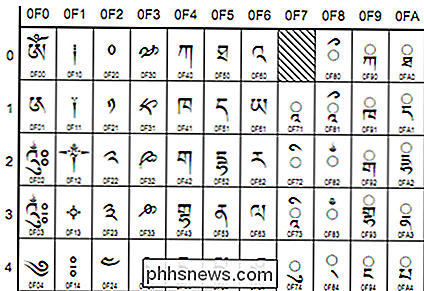
- Unicode - Denna kodningsstandard syftar till universalitet. Det innehåller för närvarande 93 skript anordnade i flera kvarter, med många fler i verken. Unicode fungerar annorlunda än andra teckenuppsättningar genom att istället för direktkodning för en glyf, riktas varje värde vidare till en "kodpunkt". Dessa är hexadecimala värden som motsvarar tecken men glyferna själva tillhandahålls fristående av programmet , till exempel din webbläsare. Dessa kodpunkter är vanligtvis avbildade enligt följande: U + 0040 (som översätter till '@'). Specifika kodningar enligt Unicode-standarden är UTF-8 och UTF-16. UTF-8 försöker tillåta maximal kompatibilitet med ASCII. Det är 8-bitars men tillåter alla tecken via en substitutionsmekanism och flera par värden per tecken. UTF-16-gräsklippningar perfekt ASCII-kompatibilitet för en mer komplett 16-bitars kompatibilitet med standarden.
- ISO-10646 - Detta är inte en faktisk kodning, bara en teckenuppsättning Unicode som standardiserats av ISO. Det är mest viktigt eftersom det är teckensrepertoaren som används av HTML. Några av de mer avancerade funktioner som tillhandahålls av Unicode som möjliggör sortering och höger till vänster tillsammans med vänster-till-höger scripting saknas. Ändå fungerar det mycket bra för användning på internet eftersom det tillåter användningen av en mängd olika skript och låter webbläsaren tolka glyphs. Detta gör lokalisering något enklare.
Vad kodning ska jag använda?
Tja, fungerar ASCII för de flesta engelska talare, men inte för mycket annat. Ofta ser du ISO-8859-1, som fungerar för de flesta västeuropeiska språken. De andra versionerna av ISO-8859 arbetar för cyrilliska, arabiska, grekiska eller andra specifika skript. Om du vill visa flera skript i samma dokument eller på samma webbsida kan UTF-8 dock ge mycket bättre kompatibilitet. Det fungerar också riktigt bra för personer som använder ordinarie interpunktion, matte-symboler eller karaktärsfigurer, t.ex. kvadrater och kryssrutor.

(Flera språk i ett dokument, Skärmdump av gujaratsamachar.com)
Det finns nackdelar med varje uppsättning, dock. ASCII är begränsad i skiljetecken, så det fungerar inte otroligt bra för typografiskt korrekta ändringar. Har du någonsin typ kopiera / klistra in från Word bara för att ha någon konstig kombination av glyfer? Det är nackdelen med ISO-8859, eller mer korrekt, det antas att den är kompatibel med OS-specifika kodsidor (vi tittar på DIG, Microsoft!). UTF-8: s största nackdel är brist på korrekt stöd vid redigering och publicering. Ett annat problem är att webbläsare ofta inte tolkar och bara visar byte-ordningens märke för ett UTF-8-kodat tecken. Detta resulterar i att oönskade glyfer visas. Och självklart är det svårt för webbläsare att göra dem korrekt och för att sökmotorer ska kunna indexera dem på ett korrekt sätt, och deklarerar att en kodning och användning av tecken från en annan utan att de förklarar / hänvisar dem ordentligt på en webbsida.
För egna dokument, manuskript och så vidare kan du använda allt du behöver för att få jobbet gjort. Så långt som webben går, verkar det som om de flesta är överens om att använda en UTF-8-version som inte använder ett byte-ordning, men det är inte helt enhälligt. Som du kan se har varje teckenkodning sin egen användning, sammanhang och styrkor och svagheter. Som slutanvändare behöver du förmodligen inte hantera detta, men nu kan du ta extra steg framåt om du väljer det.

Så här öppnar du zip-filer på en iPhone eller iPad
Om du använder en iOS-enhet vet du att det är ett ganska komplett system och fungerar väldigt bra. Men du kan ha haft problem med att öppna komprimerade zip-filer, så vi pratar idag om hur du bäst hanterar zip-filer på din iPhone eller iPad. Apples iOS har faktiskt haft stöd, om än begränsat, för zip-filer sedan iOS 7 men det fungerar bara med meddelanden och mail.

Hur (och varför) ersätter dina uttag med GFCI-utlopp
I stort sett alla hus där ett utlopp ligger nära en vattenkälla hittar du vanligtvis det som kallas en jordfelskrets avbrott (GFCI). Detta är en typ av uttag som är avsett att snabbt stänga av strömmen vid det uttaget när det upptäcker en kortslutning eller ett jordfel. Varning : Detta är ett projekt för en självsäker DIYer.